|
Федорук В.Г.
fedoruk@wwwcdl.bmstu.ru
263-65-26
АННОТАЦИЯДанное учебное пособие предназначено для изучения
основ языка SQL - стандартного языка манипулирования данными в СУБД, реализующих
реляционную модель данных. Описывается синтаксис наиболее употребимых операторов
языка SQL, приводятся примеры. Обучающимся дается возможность в интерактивном
режиме проверить свои знания.
Учебная база данных реализована в среде СУБД
mySQL, средства доступа к ней встроены в учебное пособие.
СодержаниеКраткие
сведения из теории
Основы
синтаксиса языка SQL
Учебная
база данных
Типы
данных языка SQL
Манипулирование
таблицами
Добавление
строк в таблицу
Выборка
данных из таблиц
Манипулирование
строками таблиц
Литература
Упражнения
Краткие сведения из теорииЯзык SQL
(Structured Query Language - структурированный язык запросов) представляет собой
стандартный высокоуровневый язык описания данных и манипулирования ими в
системах управления базами данных (СУБД), построенных на основе реляционной
модели данных [1].
Язык SQL был разработан фирмой IBM в конце 70-х годов. Первый международный
стандарт языка был принят международной стандартизирующей организацией ISO в
1989 г. [2], а
новый (более полный) - в 1992 г. [3]. В
настоящее время все производители реляционных СУБД поддерживают с различной
степенью соответствия стандарт SQL92.
Единственной структурой представления данных (как прикладных, так и
системных) в реляционной базе данных (БД) является двумерная таблица. Любая
таблица может рассматриваться как одна из форм представления
теоретико-множественного понятия отношение (relation), отсюда название
модели данных - ?реляционная?.
В реляционной модели данных таблица обладает
следующими основными свойствами:
- идентифицуруется уникальным именем;
- имеет конечное (как правило, постоянное) ненулевое количество столбцов;
- имеет конечное (возможно, нулевое) число строк;
- столбцы таблицы идентифицируются своими уникальными именами и номерами;
- содержимое всех ячеек столбца принадлежит одному типу данных (т.е. столбцы
однородны), содержимым ячейки столбца не может быть таблица;
- строки таблицы не имеют какой-либо упорядоченности и идентифицируются
только своим содержимым (т.е. понятие ?номер строки? не определено);
- в общем случае ячейки таблицы могут оставаться ?пустыми? (т.е. не
содержать какого-либо значения), такое их состояние обозначается как NULL.
Примечание. Необходимо иметь в виду, что видимая пользователям
СУБД логическая организация данных (в нашем случае с помощью реляционной модели)
может очень слабо коррелироваться с их физической организацией в памяти ЭВМ.
На содержимое таблиц допустимо накладывать ограничения в виде:
- требования уникальности содержимого каждой ячейки какого-либо столбца
и/или совокупности ячеек в строке, относящихся к нескольким столбцам;
- запрета для какого-либо столбца (столбцов) иметь ?пустые? (NULL) ячейки.
Ограничение в виде требования уникальности тесно связано с понятием
ключа таблицы. Ключом таблицы называется столбец или комбинация столбцов,
содержимое ячеек которого(ых) используется для прямого доступа (?быстрого?
определения местоположения) к строкам таблицы. Различают ключи первичный (он
может быть только единственным для каждой таблицы) и вторичные. Первичный ключ
уникален и однозначно идентифицирует строку таблицы. Столбец строки,
определенный в качестве первичного ключа, не может содержать ?пустое? (NULL)
значение в какой-либо своей ячейке. Вторичный ключ определяет местоположение, в
общем случае, не одной строки таблицы, а нескольких ?подобных? (в любом случае
ускоряя доступ к ним, хотя не в такой степени как ключ первичный).
Ключи
используются внутренними механизмами СУБД для оптимизации затрат на доступ к
строкам таблиц (путем, например, их физического упорядочения по значениям ключей
или построения двоичного дерева поиска).
Основными операциями над таблицами являются следующие.
- Проекция - построение новой таблицы из исходной путем включения в
нее избранных столбцов исходной таблицы.
- Ограничение - построение новой таблицы из исходной путем включения
в нее тех строк исходной таблицы, которые отвечают некоторому критерию в виде
логического условия (ограничения).
- Объединение - построение новой таблицы из 2-ух или более исходных
путем включения в нее всех строк исходных таблиц (при условии, конечно, что
они подобны).
- Декартово произведение - построение новой таблицы из 2-ух или более
исходных путем включения в нее строк, образованных всеми возможными вариантами
конкатенации (слияния) строк исходных таблиц. Количество строк новой таблицы
определяется как произведение количеств строк всех исходных таблиц.
Пречисленные выше 4 операции создают базис, на основе которого может
быть построено большинство (но не все) практически полезных запросов на
извлечение информации из реляционной БД.
Примечание. Набор операций
будет полным, если дополнить его операциями пересечения и вычитания. Однако в
данном пособии реализация этих операций в языке SQL не рассматривается.
Кроме перечисленных выше в языке SQL реализованы операции модификации
содержимого строк таблицы и пополнения таблицы новыми строками (что теоретически
может рассматриваться как операция объединения), а также операции управления
таблицами.
Рассмотренные выше операции над таблицами реляционной БД обладая
функциональной полнотой, будучи реализованы на практике в своем ?чистом?
каноническом виде, как правило, крайне неэкономичны (в первую очередь это
относится к комбинации операций ограничения и декартового произведения).
Разработчики реальных реляционных СУБД прибегают ко всевозможным приемам и
?ухищрениям? для минизации вычислительных затрат (в первую очередь, машинного
времени) при выполнении этих операций. Общим способом, нашедшим отражение в
языке SQL, повышения эффективности выполнения запросов в реляционных СУБД
являются импользование ключей индексов.
Индексом называется скрытая от пользователя вспомогательная
управляющая структура, обеспечивающая прямой (или ?квази?-прямой) метод доступа
к строкам таблицы, позволяющий исключить последовательный просмотр всех строк
таблицы для обнаружения отвечающих некоторому критерию поиска. Индексы неявным
образом (скрытно от пользователя) автоматически создаются для всех ключей
таблицы.
В настоящее время наибольшее распространение получили реляционные SQL
СУБД двух групп:
- мощные крупные коммерческие СУБД, ориентированные на хранение огромных
объемов информации (от гигабайт);
- мобильные компактные свободно распространяемые (в том числе и в исходных
кодах) СУБД, использование которых оправдано и для БД объемом всего лишь в
десятки килобайт.
Наиболее известными СУБД первой группы являются:
К наиболее популярным СУБД второй группы относятся:
В данном учебном пособии практические упражнения, которые может
выполнить обучающийся после изучения основ языка SQL, реализуются средствами
СУБД mySQL.
Все перечисленные выше СУБД построены по принципу ?клиент-сервер?, как это
показано на рисунке ниже.
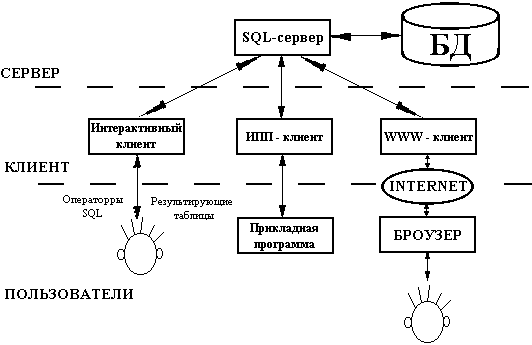 SQL-сервер реализует собственно хранение данных и
манипулирование ими. Он принимает запросы на языке SQL от своих клиентов,
выполняет их и возвращает результаты (чаще всего в виде вновь построенных
таблиц) клиентам. Для общения с клиентами используется специальный протокол (как
правило, реализованный в виде протокола прикладного уровня стека сетевых
протоколов TCP/IP).
SQL-сервер реализует собственно хранение данных и
манипулирование ими. Он принимает запросы на языке SQL от своих клиентов,
выполняет их и возвращает результаты (чаще всего в виде вновь построенных
таблиц) клиентам. Для общения с клиентами используется специальный протокол (как
правило, реализованный в виде протокола прикладного уровня стека сетевых
протоколов TCP/IP).
Клиентскую часть СУБД составляют клиенты трех основных типов.
- Интерактивные клиенты, обеспечивающие пользователю-человеку возможность
общения с SQL-сервером непосредственно с помощью языка SQL.
- ИПП-клиенты, обеспечивающие интерфейс прикладного программирования (ИПП)
прикладным программам, использующим средства SQL-сервера. Такой ИПП может быть
средством общения прикладной программы с SQL-сервером на языке SQL или набором
стандартных функций доступа к реляционной SQL БД без формирования символьных
строк запросов (например, стандартный интерфейс ODBC).
- WWW-клиенты, встраиваемые в World Wide Web-сервера и обеспечивающие доступ
к информационным возможностям SQL-сервера пользователям сети Internet по
протоколу HTTP (протоколу передачи гипертекстовых документов).
Именно
WWW-клиент СУБД mySQL используется в учебном пособии для выполнения практических
упражнений.
Основы синтаксиса языка SQL?Программа? на
языке SQL представляет собой простую линейную последовательность операторов
языка SQL. Язык SQL в своем ?чистом? виде операторов управления порядком
выполнения запросов к БД (типа циклов, ветвлений, переходов) не имеет.
Операторы языка SQL строятся с применением:
- зарезервированных ключевых слов;
- идентификаторов (имен) таблиц и столбцов таблиц;
- логических, арифметических и строковых выражений, используемых для
формирования критериев поиска информации в БД и для вычисления значений ячеек
результирующих таблиц;
- идентификаторов (имен) операций и функций, используемых в выражениях.
Все ключевые слова, имена функций и, как правило, имена таблиц и
столбцов представляются 7-мибитными символами кодировки ASCII (иначе говоря -
латинскими буквами).
В языке SQL не делается различия между прописными
(большими) и строчными (маленькими) буквами, т.е., например, строки ?SELECT?,
?Select?, ?select? представляют собой одно и то же ключевое слово.
Для
конструирования имен таблиц и их столбцов допустимо использовать буквы, цифры и
знак ?_? (подчеркивание), но первым символом имени обязательно должна быть
буква.
Запрещено использование ключевых слов и имен функций в качестве
идентификаторов таблиц и имен столбцов. Полный список ключевых слов и имен
функций (а он весьма обширен) можно найти в документации на конкретную СУБД.
Оператор начинается с ключевого слова-глагола (например, ?CREATE? - создать,
?UPDATE? - обновить, ?SELECT? - выбрать и т.п.) и заканчивается знаком ?;?
(точка с запятой). Оператор записывается в свободном формате и может занимать
несколько строк. Допустимыми разделителями лексических единиц в операторе
являются:
- один или несколько пробелов,
- один или несколько символов табуляции,
- один или несколько символов ?новая строка?.
При описании
операторов языка SQL в учебном пособии используются следующие соглашения.
- Прописными (большими) буквами (напрмер, SELECT, FROM, WHERE) набраны
зарезервированные слова.
- Курсивом (например, имя_табл, сложн_условие) набраны
переменные (нетерминальные символы), подлежащие замене в реальном операторе
конструкцией из терминальных символов (идентификаторов, знаков операций, имен
функций и т.п.).
- В квадратные скобки (?[...]?) заключается необязательная часть оператора,
которую можно опустить при создании реального оператора (сами квадратные
скобки в текст оператора не включаются).
- Вертикальная черта (?|?) означает возможность выбора (?или?) из двух или
нескольких вариантов синтаксической конструкции (сама вертикальная черта в
текст оператора не включается). Подчеркнутый вариант (например, в ?[
ALL | DISTINCT }?) является умолчательным.
- Последовательность символов ?, ...? обозначает возможность повторения
произвольное количество раз (в том числе и нулевое) предшествующей запятой
конструкции. Символ ?,? включается в реальный оператор в качестве разделителя
перед каждым повторением конструкции.
К сожалению, разработчики
реальных СУБД неаккуратно обращаются с требованиями стандартов языка SQL в части
комментариев. Поэтому комментарии при использовании в различных СУБД в текстах
?программ? на языке SQL могут помечаться следующими способами:
- от двойного минуса (?--?) до конца строки;
- от символа ?#? до конца строки;
- между последовательностями ?/*? и ?*/? (стиль комментариев языка СИ).
Учебная база данныхВ качестве примера в
учебном пособии рассматривается БД, содержащая информацию, используемую для
решения двумерной (плоской) задачи анализа напряженно-деформированного состояния
механического объекта методом конечных элементов [4].
Метод конечных элементов (МКЭ) - универсальный метод решения краевых задач
(систем дифференциальных уравнений в частных производных с краевыми условиями),
к которым относится и задача анализа (моделирования) напряженно-деформированного
состояния плоских механических объектов. Одним из основных этапов метода
является этап разбиения ?тела? моделируемого объекта на элементарные участки,
называемые конечными элементами (КЭ). Для плоских объектов чаще всего такие КЭ
представляют собой треугольники. Пример покрытия объекта (типа рычага) сеткой
конечных элементов представлен ниже.
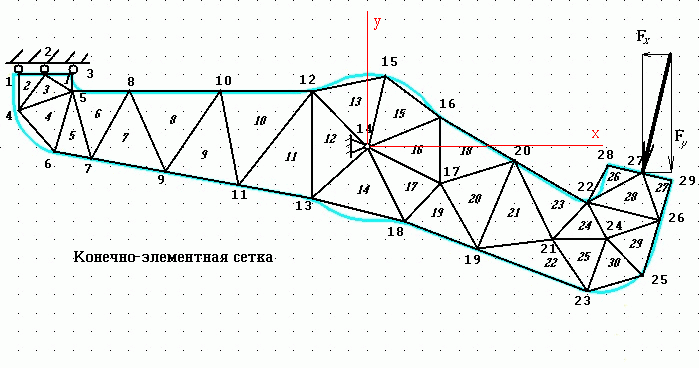 В дальнейшем МКЭ
обеспечивает нахождение численных значений фазовых переменных , характеризующих
состояние объекта (в нашем случае напряжений поля сил и деформаций), в вершинах
таких треугольников, называемых узлами (nodes). В дальнейшем МКЭ
обеспечивает нахождение численных значений фазовых переменных , характеризующих
состояние объекта (в нашем случае напряжений поля сил и деформаций), в вершинах
таких треугольников, называемых узлами (nodes).
Для идентификации узлов и КЭ их помечают номерами (числами из натурального
ряда 1...). Задача ручного разбиения двумерного (а тем более трехмерного)
объекта на КЭ является трудоемкой и нетривиальной, поэтому в реальных
промышленных системах анализа, реализующих МКЭ, существует, как правило,
несколько автоматических процедур покрытия исследуемой области сеткой КЭ. Однако
сгенерированная любым способом (автоматически/вручную/комбинированно) сетка КЭ
нуждается в проверке некоторым набором правил ее корректности, обеспечивающих
минимальность вычислительных затрат и точность получаемых результатов.
Требуется, например, чтобы форма треугольных КЭ как можно теснее приближалась
к равносторонней (это влияет на точность получаемого решения). Для уменьшения
вычислительных затрат желательно иметь минимальную разность идентификаторов
вершин для каждого КЭ.
В задачах исследования поведения механических объектов под воздействием
внешних факторов с каждым КЭ связан набор свойств материала, покрываемого КЭ, в
состав которого входят, например, плотность (density) среды, модуль Юнга
(elastic module), коэффициент Пуассона (Poisson's coefficient), прочность
(strength) и др.
Задачей МКЭ является исследование поведения объектов (в нашем примере
механических) при различных граничных условиях (воздействиях внешней среды), в
состав которых входят:
- произвольно направленная сила;
- произвольно направленный момент сил;
- ?заделка?, жестко фиксирующая положение узла сетки по линейным координатам
и углу вращения;
- шарнир, позволяющий узлу свободно ?вращаться? относительно его
фиксируемого положения по линейным координатам;
- ?каток?, дающий узлу возможность свободно перемещаться по оси x или y.
Описанная выше информация является предметом хранения и
манипулирования в учебной БД, используемой в данном пособии. Основу БД
составляют четыре таблицы:
- таблица ?nodes?, содержащая информацию об узлах КЭ-сетки (идентификатор,
x- и y-координаты);
- таблица ?elements?, содержащая информацию обо всех КЭ, составляющих сетку
(номер КЭ, идентификаторы трех вершин, наименование материала);
- таблица ?materials?, содержащая информацию о свойствах различных
конструкционных материалов (наименование, плотность, модуль Юнга, коэффициент
Пуассона, прочность);
- таблица ?loadings?, содержащая информацию о граничных условиях решаемой
задачи (вид условия, его ?направление?, номер узла приложения, числовое
значение).
Типы данных языка SQLТипы данных,
используемые в языке SQL для хранения информации в столбцах таблиц БД, весьма
разнообразны. К сожалению, производители конкретных реляционных СУБД
считают своим долгом ?улучшить? множество типов данных, регламентируемых
стандартом, реализуя свои собственные версии и расширения.
Автором
учебного пособия в качестве базовых предлагается считать следующие типы
данных:
- INT[(len)] - целое число длиной 4 байта, представляемое при выводе
максимально len цифрами;
- SMALLINT[(len)] - целое число длиной 2 байта, представляемое при
выводе максимально len цифрами;
- FLOAT[(len,dec)] - действительное число, представляемое при
выводе максимально len символами с dec цифрами после десятичной
точки;
- CHAR(size) - строка символов фиксированной длины размером
size символов;
- VARCHAR(size) - строка символов переменной длины максимальным
размером до size символов;
- BLOB (Binary Large OBject) - массив произвольных (двоичных) байтов
(максимальный размер зависит от реализации, обычно это 65535 байт); этот тип
данных может использоваться, например, для хранения изображений;
- DATE - астрономическая дата;
- TIME - астрономическое время.
Символьные константы (типа CHAR и
VARCHAR) записываются как последовательности символов, заключенные в одиночные
апострофы, например ?brass? (латунь).
Десятичные константы (типа FLOAT)
могут записываться в ?научной? нотации как последовательности следующих
компонент:
- знак числа;
- десятичное число с точкой;
- символ ?е?;
- знак (?+? или ?-?) показателя степени;
- целое число, играющее роль показателя степени числа 10.
Например,
десятичное число -0,123 может быть записано как -12.3е-2.
Отличие типов данных CHAR и VARCHAR заключается в том, что для хранения в
таблице строк символов типа CHAR используется точно size байт (хотя
содержание хранимых строк может быть значительно короче), в то время как для
строк типа VARCHAR незанятые символами строк (?пустые?) байты в таблице не
хранятся.
Подчеркнем, что величины len и dec (в отличие от
size) не влияют на размер хранения данных в таблице, а только форматируют
вывод данных из таблицы.
Примечание. Тип данных BLOB поддерживается непосредственно не всеми
СУБД, однако каждая из них предлагает его аналог (например, BINARY или IMAGE).
Рекомендация. Разрабатывая мобильное приложение (рассчитанное на
работу в среде различных СУБД), старайтесь без необходимости избегать
использования необязательных возможностей в описании типов данных.
Манипулирование таблицамиДля
создания, изменения и удаления таблиц в SQL БД используются операторы CREATE
TABLE, ALTER TABLE и DROP TABLE.
Создание таблицыСоздание таблицы в БД
реализуется оператором CREATE TABLE, имеющим следующий синтаксис
CREATE TABLE имя_табл (с_спецификация, ...); где
с_спецификация имеет разнообразный синтаксис. Здесь же рассматриваются
наиболее часто используемые ее формы.
- Описание столбца таблицы
имя_столбца тип_данных [NULL] где
имя_столбца - имя столбца таблицы, а тип_данных -
спецификация одного из типов данных, рассмотренных в разделе ?Типы
данных языка SQL?. Необязательное ключевое слово NULL означает, что
ячейкам данного столбца разрешено быть пустыми (т.е. не содержать какого-либо
значения).
- Описание столбца таблицы
имя_столбца тип_данных NOT NULL [DEFAULT по_умолч] [PRIMARY KEY] где
конструкция NOT NULL запрещает иметь в таблице пустые ячейки в данном столбце.
Конструкция PRIMARY KEY указывает, что содержимое столбца будет играть роль
первичного ключа для создаваемой таблицы. Конструкция DEFAULT по_умолч
переопределяет имеющееся для столбцов каждого типа данных значение ?по
умолчанию? (например, 0 для числовых типов), используемое при добавлении в
таблицу оператором INSERT
INTO строк, не содержащих значений в этом столбце.
- Описание первичного ключа
PRIMARY KEY имя_ключа (имя_столбца, ...) Эта
спецификация позволяет задать первичный ключ для таблицы в виде композиции
содержимого нескольких столбцов.
- Описание вторичного ключа
KEY имя_ключа (имя_столбца, ...)
ПримерыНиже приводятся примеры использования оператора
CREATE TABLE для создания четырех таблиц учебной БД. CREATE TABLE nodes ( id SMALLINT NOT NULL PRIMARY KEY, # номер узла x FLOAT NOT NULL, # x-координата y FLOAT NOT NULL); # y-координата
CREATE TABLE elements ( id SMALLINT NOT NULL PRIMARY KEY, # номер КЭ n1 SMALLINT NOT NULL, # номер первой вершины n2 SMALLINT NOT NULL, # номер второй вершины n3 SMALLINT NOT NULL, # номер третьей вершины props CHAR(12) NOT NULL DEFAULT 'steel'); Столбец
props таблицы elements предназначен для хранения названия материала КЭ и не
может содержать ?пустых? полей, его значением ?по умолчанию? является строка
символов ?steel? (сталь). CREATE TABLE materials ( name CHAR(12) NOT NULL PRIMARY KEY, # название материала density FLOAT NOT NULL, # плотность elastics FLOAT NOT NULL, # модуль Юнга poisson FLOAT NOT NULL, # к-т Пуассона strength FLOAT NOT NULL); # прочность CREATE TABLE loadings ( type CHAR(1) NOT NULL, # тип граничного условия direction CHAR(1), # направление действия node SMALLINT NOT NULL, # номер узла приложения value FLOAT, # числовое значение KEY key_node (node) ); # вторичный ключ В
таблице граничных условий loadings поля столбцов direction и value могут быть
пустыми (иметь значение NULL), поскольку не все виды нагрузок имеют направление
действия и/или величину.
Номер узла node приложения граничного условия
определяется как ключ поиска в таблице, т.к. типичный запрос на поиск в таблице
loadings - это запрос на определение граничных условий для конкретного узла.
Однако этот ключ не может быть первичным, поскольку к одному узлу допустимо
приложение нескольких граничных условий (например, момент внешних сил в
шарнире).
Следует отметить, что в этой таблице первичный ключ может быть
сконструирован только составным из столбцов type, direction и node.
Модификация таблицыМодификация
существующей таблицы в БД реализуется оператором ALTER TABLE, имеющим следующий
синтаксис
ALTER TABLE имя_табл м_специкация [,м_спецификация ...] где
м_спецификация имеет различные формы. Ниже рассматриваюся наиболее часто
используемые.
- Добавление нового столбца
ADD COLUMN с_спецификация где
с_спецификация - описание добавляемого столбца в том виде, как оно
используется для создания таблицы оператором CREATE
TABLE.
- Удаление первичного ключа для таблицы
DROP PRIMARY KEY
- Изменение/удаление значения ?по умолчанию?
ALTER COLUMN имя_столбца SET по_умолч
или
ALTER COLUMN имя_столбца DROP DEFAULT Пример
Предположим в нашей задаче моделирования состояния плоского механического
объекта возникла необходимость учесть дополнительно тепловые эффекты. Для этого,
в частности, необходимо иметь сведения о теплофизических параметрах материала
объекта (теплоемкости и теплопроводности). Включение дополнительных сведений в
таблицу materials требует ее расширения двумя новыми столбцами, что можно
реализовать таким оператором языка SQL: ALTER TABLE materials
ADD COLUMN capacity FLOAT NOT NULL, # теплоемкость
ADD COLUMN conductivity FLOAT NOT NULL; # теплопроводность
Удаление таблицыУдаление одной или сразу
нескольких таблиц из БД реализуется оператором DROP TABLE, имеющим следующий
простой синтаксис
DROP TABLE имя_табл, ... Подчеркнем, что
оператор DROP TABLE удаляет не только все содержимое таблицы, но и само описание
таблицы из БД. Если требуется удалить только содержимое таблицы, то необходимо
использовать оператор DELETE
FROM.
Добавление строк в таблицуДля добавления
строк в таблицу SQL базы данных используется оператор INSERT INTO. Основные его
синтаксические формы описываются ниже.
- Добавление строки перечислением значений всех ее ячеек
INSERT INTO имя_табл VALUES (знач, ...); где
знач - константное значение ячейки строки. Значения ячеек в списке
должны соответствовать порядку перечисления спецификаций столбцов таблицы в
операторе CREATE
TABLE. Допустимо в качестве знач указывать ключевое слово NULL, что
означает отсутствие значения для соответствующей ячейки строки.
Перед
добавлением новой строки в таблицу СУБД проверяет допустимость перечисленных
значений, используя описание столбцов таблицы из оператора CREATE TABLE.
- Добавление строки с использованием списка имен столбцов
INSERT INTO имя_табл (имя_столбца, ...) VALUES (знач, ...); Здесь
списки имен столбцов и значений ячеек добавляемой строки должны быть
согласованы, хотя нет никаких требований к их порядку. Допустимо опускать в
списках информацию о некоторых ячейках строки, при этом
- ячейки, соответствующие столбцам со спецификацией NULL в операторе
CREATE TABLE, будут пустыми;
- ячейки, соответствующие столбцам со спецификацией NOT NULL в операторе
CREATE TABLE, заполняются значениями ?по умолчанию?.
- Добавление строк по результатам запроса к БД
INSERT INTO имя_табл [(имя_столбца, ...)] SELECT ... Такой
оператор дает возможность добавить в таблицу 0, 1 или сразу несколько новых
строк, полученных в результате запроса к базе данных, реализуемого оператором
SELECT. Пример
Добавление информации о новом узле КЭ-сетки в таблицу nodes: INSERT INTO nodes VALUES (25, 6.3, 1.8); Отметим, что
добавление новой строки будет удачным только в том случае, если узла с таким же
идентификатором в таблице nodes еще нет - дело в том, что столбец id этой
таблицы объявлен первичным ключом и, следоваательно, значения всех его ячеек
должны быть уникальны.
Пример
Добавление информации о новом КЭ в таблицу elements:
INSERT INTO elements
(n1, n2, n3, id) VALUES
(14, 25, 18, 46); В результате в таблице elements
появится новая строка, содержащая в поле props значение ?steel?, как
умолчательное значение, определенное при создании таблицы.
Пример
Включение в таблицу materials сведений о новом
материале: INSERT INTO materials VALUES (
'wood', 0.6, 2.0, 0.12, 50); Пример
Добавление в таблицу граничных условий loadings информации об
ориентированном горизонтально ?катке? в узле 2: INSERT INTO loadings VALUES (
'r', 'x', 2, NULL);
Выборка данных из таблицДля извлечения
данных, содержащихся в таблицах SQL БД, используется оператор SELECT, имеющий в
общем случае сложный и многовариантный синтаксис. В данном учебном пособии
рассматриваются только несложные и наиболее часто используемые примеры
конструкций оператора SELECT.
Упрощенно оператор SELECT выглядит следующим
образом: SELECT [ALL | DISTINCT] в_выражение, ... FROM имя_табл [син_табл], ... [WHERE сложн_условие] [GROUP BY полн_имя_столбца|ном_столбца, ...] [ORDER BY полн_имя_столбца|ном_столбца [ASC|DESC], ...] [HAVING сложн_условие]; Результатом
работы оператора является выводимая на стандартный вывод (экран дисплея) вновь
построенная таблица, для которой
- количество и смысл (семантика) столбцов определяется списком элементов
в_выражение;
- содержимое строк определяется содержимым исходных таблиц из списка FROM и
критерием выборки, задаваемым сложн_условие.
При описании
синтаксиса оператора SELECT использованы следующие обозначения:
- син_табл - необязательный синоним имени таблицы, используемый для
сокращения длины записи выражений и условий в операторе SELECT.
- полн_имя_столбца - полное имя столбца в виде
[имя_табл|син_табл.]имя_столбца Конкретизирующий
таблицу префикс в имени столбца необходим только для различения столбцов,
имеющих одинаковое имя в разных таблицах из списка FROM.
- ном_столбца - номер столбца результирующей таблицы.
Описание столбцов результирующей
таблицы 1. Специальным (и часто используемым) видом
в_выражение является символ ?*?, имеющий смысл ?все столбцы таблиц из
списка FROM?.
Пример
Вывод всего содержимого таблицы
materials. SELECT * FROM materials;
+--------------+---------+----------+---------+----------+
| name | density | elastics | poisson | strength |
+--------------+---------+----------+---------+----------+
| steel | 7.80 | 200.00 | 0.25 | 1000.00 |
| aluminium | 2.70 | 65.00 | 0.34 | 600.00 |
| concrete | 5.60 | 25.00 | 0.12 | 300.00 |
| duraluminium | 2.80 | 70.00 | 0.31 | 700.00 |
| titanium | 4.50 | 116.00 | 0.32 | 950.00 |
| brass | 8.50 | 93.00 | 0.37 | 300.00 |
+--------------+---------+----------+---------+----------+ 2.
Простым (и также часто используемым) случаем в_выражение является полное
имя столбца одной из таблиц списка FROM.
Пример
Пусть
необходимо определить идентификаторы всех узлов КЭ-сетки, к которым приложено
какое-либо граничное условие, при этом необходимо знать тип приложенного
условия. Эта задача может быть решена с помощью следующего оператора: SELECT node, type FROM loadings;
+------+------+
| node | type |
+------+------+
| 1 | r |
| 2 | r |
| 3 | r |
| 14 | h |
| 27 | f |
| 27 | f |
+------+------+ Полученная результирующая таблица содержит
дублирующие строки для узла 27. Избежать этого можно, добавив в оператор
ключевое слово DISTINCT, запрещающее включение в итоговую таблицу одинаковых
строк. SELECT DISTINCT node, type FROM loadings;
+------+------+
| node | type |
+------+------+
| 1 | r |
| 2 | r |
| 3 | r |
| 14 | h |
| 27 | f |
+------+------+ 3. В общем случае в_выражение
может представлять собой сложное скобочное выражение над содержимым столбцов
таблицы, использующее арифметические, строковые, логические операции и функции.
Наиболее часто используемые функции описаны ниже в таблицах 1, 2, 3.
Пример
Используемая нами таблица свойств материалов
materials содержит в своих столбцах density и elastics значащие разряды чисел,
выражающих, соответственно, плотность и модуль Юнга каждого материала. Для
получения реальных значений этих свойств в системе единиц измерения СИ
(кг/м3 и Па) необходимо домножить их на масштабные коэффициенты, что
реализуется следующим оператором
SELECT name, density*1000, elastics*1e+9 FROM materials;
+--------------+--------------+-----------------+
| name | density*1000 | elastics*1e+9 |
+--------------+--------------+-----------------+
| steel | 7800.00 | 200000000000.00 |
| aluminium | 2700.00 | 65000000000.00 |
| concrete | 5600.00 | 25000000000.00 |
| duraluminium | 2800.00 | 70000000000.00 |
| titanium | 4500.00 | 116000000000.00 |
| brass | 8500.00 | 93000000000.00 |
+--------------+--------------+-----------------+
Таблица 1. Арифметические функции
| Синтаксис |
Возвращаемое значение |
| ABS(x) |
абсолютное значение x |
| SQRT(x) |
квадратный корень от x |
| MAX(x, y, ...) |
значение наибольшего элемента из списка x, y, ... |
| MIN(x,y, ...) |
значение наименьшего элемента из
списка x, y, ... | Примечание. x,
y - числа или выражения, имеющие числовой результат.
Таблица 2. Строковые функции
| Синтаксис |
Возвращаемое значение |
| LEFT(s,n) |
первые n символов строки s |
| RIGHT(s.n) |
последние n символов строки s |
| SUBSTRING(s, m, n) |
строка, получаемая копированием n символов из строки s,
начиная с m-ого символа строки s |
| LCASE(s) |
строка, полученная из s преобразованием всех букв в
строчные |
| UCASE(s) |
строка, полученная из s преобразованием всех букв в
прописные |
| CONCAT(s1, s2, ...) |
строка, полученная конкатенацией (слиянием) строк s1, s2,
... |
| LENGTH(s) |
длина строки s | Примечание. s, s1,s2 -
строки или выражения, имеющие результат в виде строки. n, m - числа или
выражения, имеющие числовой результат.
Таблица 3.
Операторы и функции, возвращающие логическое значение (1 - ?истина?, 0 - ?ложь?)
| Синтаксис |
Возвращаемое значение |
x = y
x ?? y
x
? y
x ? y
x ?=
y
x ?= y |
1 (?истина?) или 0 (?ложь?) в зависимости от результата операции
сравнения (соответственно, ?равно?, ?не равно?, ?больше?, ?меньше?, ?не
больше?, ?не меньше?) |
| NOT l |
1, если l=0
0, если l=1 |
| l1 AND l2 |
результат логической операции ?И? над l1 и l2 |
| l1 OR l2 |
результат логической операции ?ИЛИ? над l1 и l2 |
| BETWEEN (x, y z) |
результат выполнения логического выражения (x?=y AND
x?=z) |
| ISNULL (v) |
1, если v имеет значение ?пусто? (NULL)
0, в
противном случае |
| IFNULL (v1, v2) |
v1, если v1 не ?пусто?
v2, в противном
случае |
| s LIKE образец |
1, при удачном сопоставлении строки s с
образец
0, в противном случае |
| s NOT LIKE образец |
0, при удачном сопоставлении строки s с
образец
1, в противном
случае | Примечание. x, y, z - числа или
выражения, имеющие числовой результат. l, l1, l2 - логические константы
(1 или 0) или логические выражения. s - строка или выражение, имеющее
результат в виде строки. v, v1, v2 - переменные или выражения.
образец - константа в виде строки символов, возможно, содержащая
метасимволы ?%? и ?_?. В образец метасимвол ?_? сопоставим с любым
одиночным символом строки s, метасимвол ?%? - с любой цепочкой символов
любой ( в том числе нулевой) длины.
Пример
Пусть необходимо при выводе информации о плотности
материалов из таблицы materials идентифицировать материалы, имеющие в своем
составе алюминий (правильнее, имеющие в своем названии упоминание об алюминии).
Эта задача может быть решена с помощью следующего оператора. SELECT name, name LIKE '%alu%', density FROM materials;
+--------------+-------------------+---------+
| name | name LIKE '%alu%' | density |
+--------------+-------------------+---------+
| steel | 0 | 7.80 |
| aluminium | 1 | 2.70 |
| concrete | 0 | 5.60 |
| duraluminium | 1 | 2.80 |
| titanium | 0 | 4.50 |
| brass | 0 | 8.50 |
+--------------+-------------------+---------+ Пример
Пусть необходимо для каждого конечного элемента определить наибольшее
значение разности идентификаторов узлов, являющихся вершинами этого конечного
элемента. Данная задача может быть решена следующим оператором SELECT id, n1, n2, n3, MAX(ABS(n1-n2),ABS(n1-n3),ABS(n2-n3)) FROM elements;
+----+----+----+----+---------------------------------------+
| id | n1 | n2 | n3 | MAX(ABS(n1-n2),ABS(n1-n3),ABS(n2-n3)) |
+----+----+----+----+---------------------------------------+
| 29 | 24 | 26 | 25 | 2 |
| 30 | 24 | 25 | 23 | 2 |
| 31 | 22 | 26 | 24 | 4 |
| 1 | 2 | 3 | 5 | &nbs
p; 3 |
| 2 | 1 | 2 | 4 | &nbs
p; 3 |
| 3 | 2 | 5 | 4 | &nbs
p; 3 |
| 4 | 4 | 5 | 6 | &nbs
p; 2 |
| 25 | 24 | 23 | 21 | 3 |
| 20 | 20 | 19 | 17 | 3 |
| 21 | 21 | 19 | 20 | 2 |
| 22 | 21 | 23 | 19 | 4 |
| 12 | 12 | 14 | 13 | 2 |
| 13 | 12 | 15 | 14 | 3 |
| 14 | 13 | 14 | 18 | 5 |
| 26 | 28 | 27 | 22 | 6 |
| 7 | 7 | 8 | 9 | &nbs
p; 2 |
| 8 | 8 | 10 | 9 | 2
|
| 9 | 9 | 10 | 11 | 2 |
| 10 | 10 | 12 | 11 | 2 |
| 11 | 11 | 12 | 13 | 2 |
| 16 | 16 | 17 | 14 | 3 |
| 17 | 18 | 17 | 14 | 4 |
| 18 | 16 | 20 | 17 | 4 |
| 19 | 19 | 18 | 17 | 2 |
| 15 | 15 | 16 | 14 | 2 |
| 27 | 27 | 29 | 26 | 3 |
| 28 | 22 | 27 | 26 | 5 |
| 5 | 5 | 7 | 6 | &nbs
p; 2 |
| 6 | 5 | 8 | 7 | &nbs
p; 3 |
| 23 | 20 | 22 | 21 | 2 |
| 24 | 24 | 21 | 22 | 3 |
+----+----+----+----+---------------------------------------+ 4. В общем случае в_выражение допускает
использование агрегативных (называемых также групповыми) функций, принимающих в
качестве своего единственного аргумента значения всех ячеек указанного столбца
результирующей таблицы. Основные такие функции представлены в таблице 4. Таблица 4. Агрегативные функции
| Синтаксис |
Возвращаемое значение |
| SUM(x) |
сумма значений столбца x результирующей таблицы |
| MAX(x) |
наибольшее значение из всех значений ячеек столбца
x |
| MIN(x) |
наименьшее значение из всех значений ячеек столбца x |
| AVG(x) |
среднее значение для всех значений ячеек столбца x |
| COUNT(x) |
общее количество ячеек в столбце
x | Примечание. Функции MAX(...) и
MIN(...) с одним аргументом являются агрегативными функциями, они же с двумя и
более аргументами - обычные функции (см. таблицу
1).
Пример
Для отыскания наибольшего значения модуля Юнга для
материалов, имеющихся в таблице materials, можно использовать следующий оператор
SELECT MAX(elastics) FROM materials;
+---------------+
| MAX(elastics) |
+---------------+
| 200.00 |
+---------------+ Пример
Следующий оператор
SELECT позволяет определить общее количество конечных элементов в КЭ-сетке из
нашего примера. SELECT COUNT(*) FROM elements;
+----------+
| COUNT(*) |
+----------+
| 31 |
+----------+
Описание критерия выборки содержимого строк
результирующей матрицыВ качестве критерия выбора информации из
таблиц списка FROM оператора SELECT выступает сложн_условие, записываемое
после ключевого слова WHERE и имеющее следующий вид:
прост_условие
или
прост_условие AND сложн_условие
или
прост_условие OR сложн_условие Типичными
вариантами прост_условие являются следующие.
- Сравнение
полн_имя_столбца @ полн_имя_столбца_или_константа где
@ - один из операторов сравнения: ? (?больше?), ? (?меньше?), ?= (? не
меньше?), ?= (?не больше?), = (?равно?), ?? (?не равно?), а
полное_имя_столбца - имя столбца, конкретизированное при необходимости
именем или синонимом имени таблицы, как это было описано выше.
- Сопоставление с образцом
полн_имя_столбца [NOT] LIKE образец где
образец имеет вид, описанный в таблице
3.
- Проверка на ?пустое? значение в ячейке стодбца
полн_имя_столбца IS [NOT] NULL При
конструировании сложн_условие допустимо использование круглых
скобок для управления порядком вычисления условий.
Примечание. Обратите внимание, что синтаксис сложн_условие
существенно ?беднее? синтаксиса в_выражение. Дело в том, что
сложн_условие используется (в том числе и на физическом уровне
организации БД) на этапе выборки из исходной (возможно, очень большой) таблицы
(таблиц) необходимых строк в результирующую. Для сокращения времени прямого
доступа к строкам таблиц они (таблицы) снабжаются ключами и индексами. Реальный
эффект от использования ключей и индексов может быть достигнут только при
условии, что запросы на поиск в таблицах используют в качестве критерия поиска
только значения ячеек столбцов в ?чистом? виде, а не в виде их комбинации в
сложном выражении.
Конструкция же в_выражение применяется, по сути
дела, к значениям столбцов уже результирующей таблицы, поэтому сложность
в_выражение на эффективность выполнения запроса практически никакого
влияния не оказывает.
Пример
Для определения координат местоположения узла 11
может использоваться следующий оператор: SELECT * FROM nodes WHERE id = 11;
+----+--------+--------+
| id | x | y |
+----+--------+--------+
| 11 | -35.00 | -10.00 |
+----+--------+--------+ Пример
Пусть
необходимо определить идентификаторы всех конечных элементов, имеющих в качестве
одной из своих вершин узел 20. Эта задача может быть решена следующим оператором
SELECT SELECT id FROM elements
WHERE n1 = 20 OR n2 = 20 OR n3 = 20;
+----+
| id |
+----+
| 20 |
| 21 |
| 18 |
| 23 |
+----+ Пример
Для определения
идентификаторов узлов КЭ-сетки, расположенных в первом квадранте системы
координат можно использовать следующий оператор SELECT * FROM nodes
WHERE x ?= 0 AND y ?= 0;
+----+-------+-------+
| id | x | y |
+----+-------+-------+
| 14 | 0.00 | 0.00 |
| 15 | 5.00 | 20.00 |
| 16 | 20.00 | 8.00 |
+----+-------+-------+ Пример
Следующий
оператор SELECT может быть использован для определения граничных условий,
имеющих в качестве одной из своих характеристик численное значение величины SELECT * FROM loadings WHERE value IS NOT NULL;
+------+-----------+------+--------+
| type | direction | node | value |
+------+-----------+------+--------+
| f | y | 27 | -50.00 |
| f | x | 27 | -10.00 |
+------+-----------+------+--------+
Упорядочивание и группирование строк результирующей
таблицыДля обеспечения структурированности в расположении строк
результирующей таблицы в операторе SELECT используются конструкции GROUP BY и
ORDER BY.
- Упорядочение строк достигается перечислением полных имен столбцов, по
которым в возрастающем (ASC) или убывающем (DESC) порядке сортируются
строки результирующей таблицы. При этом строки упорядочиваются в первую
очередь по столбцу, указанному первым в списке ORDER BY. Затем, если среди
значений ячеек первого столбца есть повторяющиеся, производится упорядочение
по второму столбцу и так далее.
Пример
Для вывода информации об узлах КЭ-сетки в
убывающем порядке их (узлов) идентификаторов может быть использован следующий
оператор: SELECT * FROM nodes ORDER BY id DESC;
+----+--------+--------+
| id | x | y |
+----+--------+--------+
| 29 | 83.00 | -9.00 |
| 28 | 65.00 | -5.00 |
| 27 | 75.00 | -7.00 |
| 26 | 80.00 | -20.00 |
| 25 | 75.00 | -35.00 |
| 24 | 65.00 | -25.00 |
| 23 | 60.00 | -39.00 |
| 22 | 60.00 | -15.00 |
| 21 | 50.00 | -25.00 |
| 20 | 40.00 | -3.00 |
| 19 | 30.00 | -27.00 |
| 18 | 10.00 | -20.00 |
| 17 | 20.00 | -10.00 |
| 16 | 20.00 | 8.00 |
| 15 | 5.00 | 20.00 |
| 14 | 0.00 | 0.00 |
| 13 | -15.00 | -14.00 |
| 12 | -15.00 | 15.00 |
| 11 | -35.00 | -10.00 |
| 10 | -40.00 | 15.00 |
| 9 | -55.00 | -6.00 |
| 8 | -65.00 | 15.00 |
| 7 | -75.00 | -3.00 |
| 6 | -85.00 | -1.00 |
| 5 | -80.00 | 15.00 |
| 4 | -95.00 | 10.00 |
| 3 | -80.00 | 20.00 |
| 2 | -87.50 | 20.00 |
| 1 | -95.00 | 20.00 |
+----+--------+--------+ Пример
Пусть
необходимо вывести информацию о конечных элементах, упорядочив ее;
- в первую очередь по идентификаторам узлов, являющихся первой вершиной
конечного элемента;
- во вторую очередь по идентификаторам узлов, являющихся второй вершиной
конечного элемента;
Для решения этой задачи можно использовать
следующий оператор SELECT * FROM elements ORDER BY n1, n2;
+----+----+----+----+-------+
| id | n1 | n2 | n3 | props |
+----+----+----+----+-------+
| 2 | 1 | 2 | 4 | steel |
| 1 | 2 | 3 | 5 | steel |
| 3 | 2 | 5 | 4 | steel |
| 4 | 4 | 5 | 6 | steel |
| 5 | 5 | 7 | 6 | steel |
| 6 | 5 | 8 | 7 | steel |
| 7 | 7 | 8 | 9 | steel |
| 8 | 8 | 10 | 9 | steel |
| 9 | 9 | 10 | 11 | steel |
| 10 | 10 | 12 | 11 | steel |
| 11 | 11 | 12 | 13 | steel |
| 12 | 12 | 14 | 13 | steel |
| 13 | 12 | 15 | 14 | steel |
| 14 | 13 | 14 | 18 | steel |
| 15 | 15 | 16 | 14 | steel |
| 16 | 16 | 17 | 14 | steel |
| 18 | 16 | 20 | 17 | steel |
| 17 | 18 | 17 | 14 | steel |
| 19 | 19 | 18 | 17 | steel |
| 20 | 20 | 19 | 17 | steel |
| 23 | 20 | 22 | 21 | steel |
| 21 | 21 | 19 | 20 | steel |
| 22 | 21 | 23 | 19 | steel |
| 31 | 22 | 26 | 24 | steel |
| 28 | 22 | 27 | 26 | steel |
| 24 | 24 | 21 | 22 | steel |
| 25 | 24 | 23 | 21 | steel |
| 30 | 24 | 25 | 23 | steel |
| 29 | 24 | 26 | 25 | steel |
| 27 | 27 | 29 | 26 | steel |
| 26 | 28 | 27 | 22 | steel |
+----+----+----+----+-------+
- Оператор SELECT может обеспечить вычисление агрегативных
функций для групп строк результирующей таблицы. Для этого используется
список полных имен столбцов в конструкции GROUP BY. Первое полное имя столбца
в списке GROUP BY используется для разбиения строк результирующей таблицы на
первичные группы, первичные группы разделяются на ?подгруппы? вторым в списке
полным именем столбца и так далее.
Оператор SELECT выводит значения агрегативных функций для самых ?малых?
подгрупп.
Пример
Пусть необходимо определить количество узлов
КЭ-сетки, охватываемых каждым видом граничных условий. Для этого может быть
использован следующий оператор SELECT type, COUNT(*) FROM loadings GROUP BY type;
+------+----------+
| type | COUNT(*) |
+------+----------+
| f | 2 |
| h | 1 |
| r | 3 |
+------+----------+ Примечание. Конструкция HAVING
сложн_условие, как необязательная составная часть предложения GROUP BY,
позволяет определять дополнительный (к WHERE сложн_условие) критерий
выборки строк в группы. Этот дополнительный критерий применяется в
режиме постпроцессорной обработки к таблице, полученной в результате
использования критерия из конструкции WHERE.
Выборка из нескольких таблицВ общем
случае оператор SELECT языка SQL дает возможность выборки информации сразу из
нескольких таблиц, перечисленных в списке FROM. На концептуальном уровне
рассмотрения (уровне реляционной модели данных) такая выборка включает в себя
два основных этапа:
- построение промежуточной таблицы, представляющей собой декартово
произведение таблиц из списка FROM (т.е. таблицы, строки которой
представляют собой все возможные сочетания строк исходных таблиц);
- копирование в результирующую таблицу всех строк промежуточной,
отвечающих критерию из WHERE сложн_условие (если таковой определен).
Пример
Пусть необходимо определить значение модуля
Юнга для конечного элемента с идентификатором 25. Эта задача может быть решена
следующим оператором SELECT id, elastics FROM elements, materials
WHERE id = 25 AND props = name;
+----+----------+
| id | elastics |
+----+----------+
| 25 | 200.00 |
+----+----------+ Примечание. Обратите внимание, что
в данном примере нигде в операторе SELECT не потребовалось использовать полные
имена столбцов различных таблиц. Объясняется это тем, что имена столбцов
таблиц elements и materials различны, и поэтому неоднозначностей в именовании
быть не может.
Примечание. Хотя концептуальная модель обработки
оператора SELECT со списком FROM из двух и более таблиц подразумевает
построение декартового произведения этих табллиц, в реальности этого не
происходит в силу ?ограниченности? синтаксиса сложн_условие из
конструкции WHERE. Так, в нашем последнем примере запрос на выборку
осуществлялся в 2 ?коротких? этапа: 1) из таблицы elements (с использованием
первичного ключа) прямым доступом извлекается строка с id=25; 2) из таблицы
materials (опять с использованием первичного ключа) прямым доступом
извлекается информация о материале ?steel? (сталь). Очевидно, что такой
?оптимизированный? подход несравненно более эффективен по сравнению с
каноническим (через декартово произведение).
Пример
Для
вывода координат трех вершин каждого конечного элемента в КЭ-сетке в одной
таблице можно использовать следующий оператор SELECT e.id, node1.x, node1.y, node2.x, node2.y, node3.x, node3.y
FROM elements e, nodes node1, nodes node2, nodes node3
WHERE e.n1 = node1.id
AND e.n2 = node2.id
AND e.n3 = node3.id;
+----+--------+--------+--------+--------+--------+--------+
| id | x | y | x | y | x | y |
+----+--------+--------+--------+--------+--------+--------+
| 29 | 65.00 | -25.00 | 80.00 | -20.00 | 75.00 | -35.00 |
| 30 | 65.00 | -25.00 | 75.00 | -35.00 | 60.00 | -39.00 |
| 31 | 60.00 | -15.00 | 80.00 | -20.00 | 65.00 | -25.00 |
| 1 | -87.50 | 20.00 | -80.00 | 20.00 | -80.00 | 15.00 |
| 2 | -95.00 | 20.00 | -87.50 | 20.00 | -95.00 | 10.00 |
| 3 | -87.50 | 20.00 | -80.00 | 15.00 | -95.00 | 10.00 |
| 4 | -95.00 | 10.00 | -80.00 | 15.00 | -85.00 | -1.00 |
| 25 | 65.00 | -25.00 | 60.00 | -39.00 | 50.00 | -25.00 |
| 20 | 40.00 | -3.00 | 30.00 | -27.00 | 20.00 | -10.00 |
| 21 | 50.00 | -25.00 | 30.00 | -27.00 | 40.00 | -3.00 |
| 22 | 50.00 | -25.00 | 60.00 | -39.00 | 30.00 | -27.00 |
| 12 | -15.00 | 15.00 | 0.00 | 0.00 | -15.00 | -14.00 |
| 13 | -15.00 | 15.00 | 5.00 | 20.00 | 0.00 | 0.00 |
| 14 | -15.00 | -14.00 | 0.00 | 0.00 | 10.00 | -20.00 |
| 26 | 65.00 | -5.00 | 75.00 | -7.00 | 60.00 | -15.00 |
| 7 | -75.00 | -3.00 | -65.00 | 15.00 | -55.00 | -6.00 |
| 8 | -65.00 | 15.00 | -40.00 | 15.00 | -55.00 | -6.00 |
| 9 | -55.00 | -6.00 | -40.00 | 15.00 | -35.00 | -10.00 |
| 10 | -40.00 | 15.00 | -15.00 | 15.00 | -35.00 | -10.00 |
| 11 | -35.00 | -10.00 | -15.00 | 15.00 | -15.00 | -14.00 |
| 16 | 20.00 | 8.00 | 20.00 | -10.00 | 0.00 | 0.00 |
| 17 | 10.00 | -20.00 | 20.00 | -10.00 | 0.00 | 0.00 |
| 18 | 20.00 | 8.00 | 40.00 | -3.00 | 20.00 | -10.00 |
| 19 | 30.00 | -27.00 | 10.00 | -20.00 | 20.00 | -10.00 |
| 15 | 5.00 | 20.00 | 20.00 | 8.00 | 0.00 | 0.00 |
| 27 | 75.00 | -7.00 | 83.00 | -9.00 | 80.00 | -20.00 |
| 28 | 60.00 | -15.00 | 75.00 | -7.00 | 80.00 | -20.00 |
| 5 | -80.00 | 15.00 | -75.00 | -3.00 | -85.00 | -1.00 |
| 6 | -80.00 | 15.00 | -65.00 | 15.00 | -75.00 | -3.00 |
| 23 | 40.00 | -3.00 | 60.00 | -15.00 | 50.00 | -25.00 |
| 24 | 65.00 | -25.00 | 50.00 | -25.00 | 60.00 | -15.00 |
+----+--------+--------+--------+--------+--------+--------+ Примечание.
Обратите внимание, что необходимая для выполнения данного запроса
промежуточная таблица в виде декартового произведения (если бы она реально
строилась) имеет размер в 31*29*29*29=756059 строк (31 строка в таблице
elements и 29 строк в таблице nodes).
Манипулирование строками
таблицДля удаления и изменения строк таблиц SQL БД применяются
операторы DELETE и UPDATE.
Удаление строкУдаление строк таблицы
реализуется оператором DELETE FROM, имеющим следующий синтаксис
DELETE FROM имя_табл [WHERE сложн_условие] где
сложн_условие имеет описанный выше синтаксис.
В результате выполнения оператора из таблицы удаляются все строки,
удовлетворяющие критерию сложн_условие. Если в операторе DELETE FROM
конструкция WHERE опущена, то удаляются все строки таблицы.
Модификация строкИзменение содержимого
строк таблицы реализуется оператором UPDATE, имеющим следующий синтаксис UPDATE имя_табл SET имя_столбца=выражение, ... [WHERE сложн_условие] где выражение - выражение
(в простейшем случае - константа), согласующееся по результату с типом данных
столбца. В выражение допустимо использование значений ячеек любых
столбцов таблицы, рассмотренных ранее операций и функций (но не агрегативных),
а также прежнего содержимого модифицуруемой ячейки. Обновлению подлежат
столбцы строк, отвечающих критерию сложн_условие. Если конструкция
WHERE в операторе отсутствует, то обновляются все строки таблицы.
Пример
Для изменения наименования материала, из которого
выполнена механическая конструкция, для всех элементов КЭ-сетки можно
использовать следующий оператор
UPDATE elements SET props='brass';
SELECT * FROM elements;
+----+----+----+----+-------+
| id | n1 | n2 | n3 | props |
+----+----+----+----+-------+
| 29 | 24 | 26 | 25 | brass |
| 30 | 24 | 25 | 23 | brass |
| 31 | 22 | 26 | 24 | brass |
| 1 | 2 | 3 | 5 | brass |
| 2 | 1 | 2 | 4 | brass |
. . .
| 28 | 22 | 27 | 26 | brass |
| 5 | 5 | 7 | 6 | brass |
| 6 | 5 | 8 | 7 | brass |
| 23 | 20 | 22 | 21 | brass |
| 24 | 24 | 21 | 22 | brass |
+----+----+----+----+-------+ Пример
В
нашей КЭ-сетке элемент 22 имеет ?неправильную? форму. Ставится задача заменить
его двумя новыми конечными элементами, имеющими форму, более близкую к
равносторонней. Эта задача может быть решена следующей последовательностью
операторов DELETE FROM elements WHERE id=22;
INSERT INTO nodes VALUES (30, 45.0, -33.5);
INSERT INTO elements VALUES (22, 21, 30, 19);
INSERT INTO elements VALUES (32, 21, 23, 30); Пример
Для решения предыдущей задачи можно также использовать и другой набор
операторов INSERT INTO nodes VALUES (30, 45.0, -33.5);
UPDATE elements SET n2 = 30 WHERE id = 22;
INSERT INTO elements VALUES (32, 21, 23, 30);
Литература
- Дж. Мартин. Организация баз данных в вычислительных
системах. - М.;Мир,1980. - 662с.
- С.Д. Кузнецов. Стандарты языка реляционных баз данных
SQL: краткий обзор. //СУБД, 1996, N2, сс. 6-36.
- С.Д. Некузнецов
- Зенкевич О., Морган К. Конечные элементы и
аппроксимации. - М.:Мир, 1979. - 318с.
Упражнения Ниже приведены
задания, которые необходимо выполнить, используя оператор SELECT выборки
информации из учебной базы данных. Выполнение некоторых заданий значительно
упростится, если учесть приведенные ниже рекомендации.
- Определить наилучший материал по показателю ?прочность/плотность?.
- Получить таблицу, содержащую значения наибольших разностей
идентификаторов узлов - вершин для каждого конечного элемента.Таблица должна
быть упорядочена по убыванию значений разностей.
- Определить максимальное значение в таблице из предыдущего задания.
- Определить протяженность механического объекта вдоль оси x.
- Определить расстояние каждого узла КЭ-сетки до начала системы координат.
- Определить расстояние каждого узла КЭ-сетки до узла, в котором приложено
граничное условие в виде горизонтальной силы (подчеркнем, не до узла с
заданным идентификатором, а до узла с заданным типом граничного условия).
- Найти наибольшее расстояние между узлами КЭ-сетки.
- Получить таблицу длин сторон всех элементов КЭ-сетки в виде
?идентификатор элемента - длина стороны 1 - длина стороны 2 - длина стороны
3?.
- Получить таблицу расстояний между узлами КЭ-сетки, соединенных сторонами
конечных элементов, в виде ?идентификатор узла 1 - идентификатор узла 2 -
длина?.
- Получить таблицу площадей всех конечных элементов. Напомним, для
вычисления площади треугольника можно использовать формулу
s = SQRT(p*(p-a)*(p-b)*(p-c)) где a, b, c - длины
сторон треугольника, а p - его полупериметр.
- Определить общую массу механического объекта при условии, что его
толщина (в направлении z) равна 5 мм.
- Получить таблицу значений отношения maxL/minL для каждого конечного
элемента с указанием тех элементов, для которых это отношение превышает
величину 1,4 (здесь maxL - наибольшая длина стороны конечного элемента, minL
- наименьшая длина стороны конечного элемента).
- Получить таблицу ?степеней? узлов КЭ-сетки. Степенью узла в теории
графов называется количество ребер, соединяющих данный узел с соседними.
- Определить для каждого узла КЭ-сетки количество ?подключенных? к нему
конечных элементов.
- Получить список идентификаторов ?угловых? узлов КЭ-сетки (назовем
унловыми узлы, являющиеся вершиной только одного элемента).
- Получить список идентификаторов конечных элементов, одна или более
сторон которых образуют границу области.
- Предложить способ определения факта расположения узла КЭ-сетки на
границе области. Выдать список всех таких узлов.
Рекомендация. В СУБД mySQL синтаксис оператора SELECT
выглядит следующим образом: SELECT [ALL|DISTINCT] в_выражение [AS син_столбца], ... FROM ... и т.д. где син_столбца -
имя, назначаемое столбцу результирующей таблицы. Это имя используется при
выводе результирующей таблицы (в ее ?шапке?) вместо текста в_выражение.
Однако, более полезно то, что син_столбца можно использовать в
в_выражение, расположенном правее в списке оператора SELECT. Это в ряде
случаев позволяет существенно уменьшить сложность конструкции
в_выражение. Необходимо также отметить, что аналогичные средства
именования (введения синонимов) столбцов результирующей таблицы предлагают все
СУБД, поддерживающие язык SQL.
|